Deep Learning ist der Begriff hinter Sprachmodellen wie ChatGPT, hinter Bilderkennungssystemen in der Produktion und hinter Algorithmen, die Betrugsmuster in Echtzeit erkennen. Für viele klingt das nach unzugänglicher Technologie. Das ist es nicht – zumindest nicht, wenn man versteht, was dahinter steckt.
Dieser Artikel erklärt, wie neuronale Netze wirklich lernen – ohne Mathematikstudium, ohne Jargon. Und mit einem Experiment, das Sie direkt im Browser selbst ausprobieren können.

Was ist Deep Learning?
Deep Learning ist ein Teilbereich des Maschinellen Lernens – und Maschinelles Lernen ist wiederum ein Teilbereich der Künstlichen Intelligenz. Wer die übergeordneten Begriffe noch nicht auseinanderhalten kann, findet eine kompakte Übersicht im Artikel KI, Machine Learning, ChatGPT: Was die Begriffe wirklich bedeuten.
Was unterscheidet Deep Learning von klassischem Maschinellen Lernen? Das „Deep" steht für Tiefe: mehrere Schichten verarbeitender Einheiten, die nacheinander immer abstraktere Merkmale aus den Eingangsdaten extrahieren. Beim klassischen Maschinellen Lernen muss ein Mensch dem System erklären, auf welche Merkmale es achten soll – beim Deep Learning erkennt das System diese Merkmale selbst.
| Klassisches ML | Deep Learning | |
|---|---|---|
| Merkmale | Manuell vorgegeben | Automatisch erlernt |
| Datenbedarf | Gering bis mittel | Groß |
| Erklärbarkeit | Hoch | Gering |
| Geeignet für | Tabellendaten, klare Regeln | Bilder, Sprache, Audiodaten |
Das macht Deep Learning besonders leistungsfähig bei komplexen, unstrukturierten Daten – und gleichzeitig rechenintensiver und datendurstiger als einfachere Ansätze.
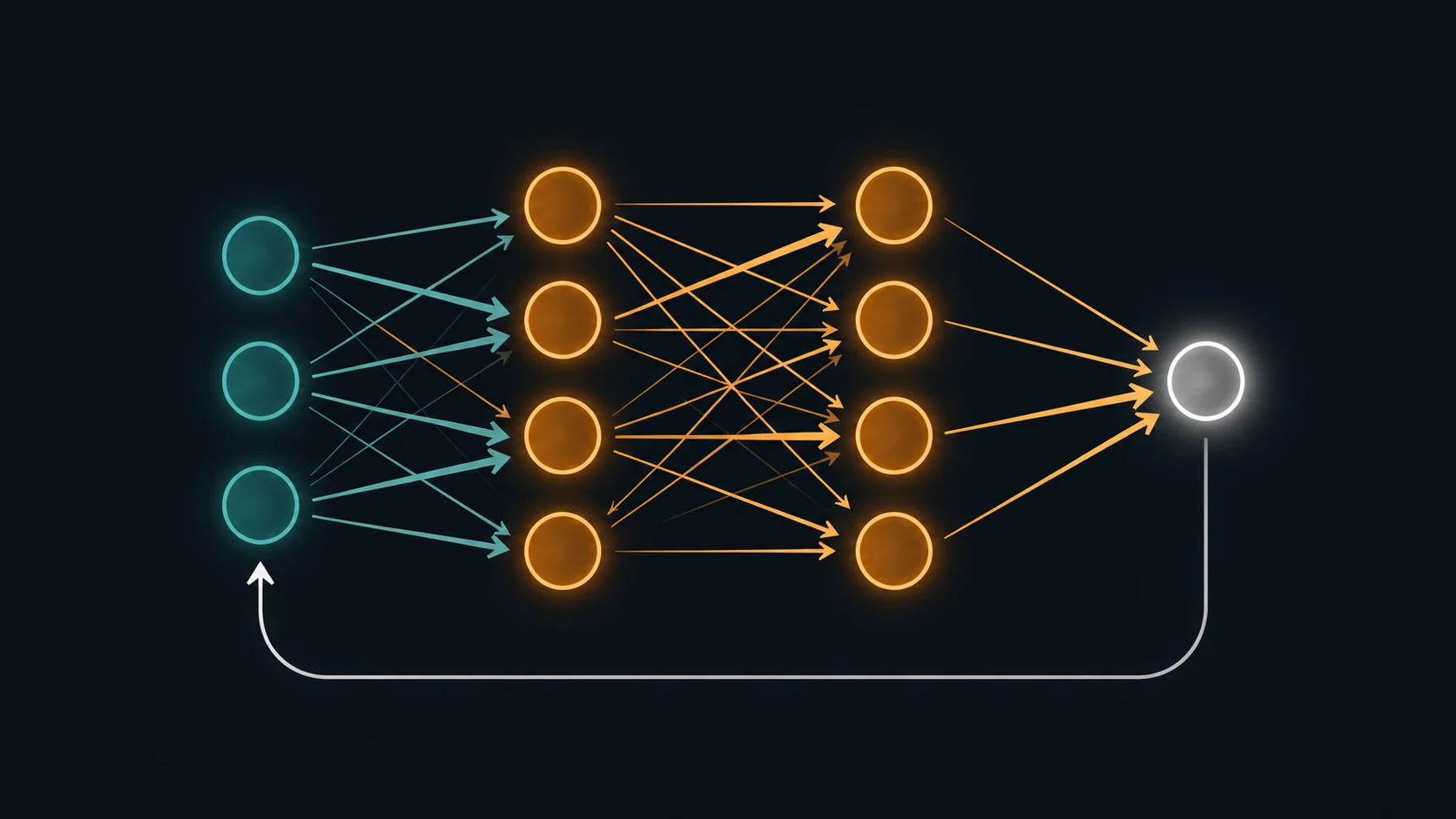
Wie ein neuronales Netz lernt
Ein künstliches neuronales Netz besteht aus drei Schichttypen: einer Eingabeschicht, einer oder mehreren verdeckten Schichten und einer Ausgabeschicht. Die Verbindungen zwischen den Neuronen haben Gewichte – Zahlenwerte, die bestimmen, wie stark ein Signal weitergegeben wird.
Stellen Sie sich ein einzelnes Neuron als Schreibtisch vor: Mehrere Eingaben kommen an, werden bewertet und gewichtet summiert. Dann entscheidet eine Aktivierungsfunktion, ob und wie stark das Neuron „feuert" – also ein Signal weitergibt. Ein einzelnes Neuron kann nur eine einfache, lineare Trennung erzeugen. Erst viele Neuronen in Kombination entstehen komplexe Entscheidungsflächen.
Der Lernprozess funktioniert in drei Schritten, die immer wieder wiederholt werden:
- Vorwärtspropagation (Forward Pass): Die Eingabedaten durchlaufen das Netz Schicht für Schicht. Am Ende entsteht eine Vorhersage – zum Beispiel: „dieses Bild zeigt einen Riss im Bauteil."
- Fehlerberechnung: Eine Verlustfunktion (Loss Function) misst, wie weit diese Vorhersage von der richtigen Antwort entfernt ist. Je größer die Abweichung, desto größer der Fehler.
- Rückwärtspropagation (Backpropagation): Der berechnete Fehler wird durch das Netz zurückgespielt. Jedes Gewicht wird angepasst – ein kleines bisschen in die Richtung, die den Fehler verringert. Diesen Prozess nennt man Gradient Descent.
Was das für Sie bedeutet
Das Netz macht eine Vorhersage, misst seinen Fehler und korrigiert sich selbst – immer und immer wieder. Training ist kein einmaliger Vorgang, sondern ein iterativer Prozess: Je mehr relevante Daten vorhanden sind, desto besser wird das Ergebnis.
Warum Features wichtiger sind als die Netzgröße
Hier liegt der häufigste Denkfehler beim Einstieg in Deep Learning: „Wenn das Modell nicht gut genug ist, bauen wir es einfach größer." Das stimmt so nicht.
Das lässt sich live und kostenlos im Browser zeigen – mit dem TensorFlow Playground, einem interaktiven Werkzeug von Google, mit dem Sie neuronale Netze direkt im Browser trainieren können, ohne eine einzige Zeile Code zu schreiben.

Das Experiment: Der Circle-Datensatz
Öffnen Sie den Playground und wählen Sie oben den Datensatz „Circle". Das Problem: Punkte liegen entweder innerhalb eines Kreises (eine Klasse) oder außerhalb (die andere Klasse). Das Netz soll lernen, diese beiden Gruppen zu trennen.
- Schritt 1 – Der Instinkt: mehr Neuronen. Starten Sie mit nur den Basis-Features x und y (die Koordinaten der Punkte). Fügen Sie vier, fünf, sechs Neuronen hinzu. Starten Sie das Training. Was passiert? Das Netz versucht, mit mehr Linien ein rundes Problem zu lösen – und scheitert. Mehr Neuronen helfen nicht.
- Schritt 2 – Den Fehler verstehen. Das Problem liegt nicht in der Netzgröße, sondern in der Information, die das Netz bekommt. Mit nur x und y sieht das Netz „dieser Punkt liegt bei Koordinate 3/4" – aber es sieht nicht, ob dieser Punkt nah am Zentrum oder weit weg davon ist.
- Schritt 3 – Die richtige Herangehensweise: Features anpassen. Schalten Sie zusätzlich die Features x² und y² ein. Starten Sie das Training neu – mit nur einem oder zwei Neuronen. Das Netz löst das Problem in Sekunden. Warum? Weil x² + y² genau der Abstand zum Ursprung ist – und damit der mathematische Kern des Circle-Problems.
Was das für Sie bedeutet
Bevor Sie in mehr Serverleistung oder größere Modelle investieren: Prüfen Sie zuerst, ob Ihre Eingabedaten die richtigen Signale enthalten. Nicht das größte Netz gewinnt – sondern das Netz, das das Problem richtig versteht.
Selbst ausprobieren: TensorFlow Playground → Circle-Datensatz öffnen – Datensatz „Circle" auswählen, Features x² und y² aktivieren, Training starten. Kein Download, kein Account, kostenlos im Browser.
Deep Learning im Unternehmenseinsatz
Deep Learning ist nicht für jede Aufgabe das richtige Werkzeug. Aber dort, wo es passt, erzeugt es messbar bessere Ergebnisse als klassische Methoden.
1. Automatische Bildprüfung in der Produktion
Kameras an der Produktionslinie erfassen Bauteile, ein Deep-Learning-Modell klassifiziert in Echtzeit: einwandfrei oder fehlerhaft. Was früher Sichtprüfung durch Mitarbeitende bedeutete, läuft heute vollautomatisch – mit konsistenter Qualität, 24 Stunden am Tag.
2. Dokumentenverarbeitung und Texterkennung
Rechnungen, Lieferscheine, Verträge: Deep Learning erkennt Strukturen in gescannten Dokumenten und extrahiert relevante Felder automatisch. Besonders wertvoll für mittelständische Unternehmen mit hohem manuellem Belegaufwand.
3. Nachfrageprognose und Lagerhaltung
Neuronale Netze erkennen saisonale Muster, externe Einflussfaktoren und langfristige Trends in historischen Verkaufsdaten – und liefern deutlich präzisere Prognosen als klassische Zeitreihenverfahren.
Wo Deep Learning nicht sinnvoll ist: Bei kleinen, sauber strukturierten Datensätzen mit klaren Regeln ist klassisches Maschinelles Lernen häufig schneller, günstiger und besser erklärbar. Deep Learning lohnt sich, wenn die Datenmenge groß ist und das Problem komplex – nicht als Standard-Werkzeug für jeden Anwendungsfall. Welche Fehler Unternehmen beim Einstieg in KI und Digitalisierung typischerweise machen, beschreibt der Artikel 5 Digitalisierungsfehler, die Mittelständler immer wieder machen.
Welche KI-Anwendungen lohnen sich für Ihren Betrieb?
Kostenlos Termin buchen Justin Kollautz
KI Spezialist · Wurzelwerk
Justin Kollautz
KI Spezialist · Wurzelwerk
Häufige Fragen zu Deep Learning
Was ist der Unterschied zwischen Deep Learning und Machine Learning?
Maschinelles Lernen ist der Oberbegriff: Das System lernt aus Daten, statt explizit programmiert zu werden. Deep Learning ist ein Spezialfall davon, der auf mehrschichtigen neuronalen Netzwerken basiert. Der zentrale Unterschied liegt in der Merkmalsextraktion: Beim klassischen Maschinellen Lernen gibt ein Mensch vor, welche Merkmale relevant sind. Deep Learning erkennt diese Merkmale selbstständig – und eignet sich deshalb besonders für Bilder, Sprache und andere unstrukturierte Daten.
Braucht Deep Learning immer sehr viele Daten?
Grundsätzlich ja – Deep-Learning-Modelle profitieren von großen Datensätzen, weil sie aus diesen Daten abstrakte Merkmale erlernen. Allerdings gibt es Techniken wie Transfer Learning, bei denen ein auf großen Datenmengen vortrainiertes Modell auf einen kleineren, spezifischen Datensatz angepasst wird. Das senkt die Datenhürde erheblich. Für einfachere Aufgaben in Unternehmen reichen oft wenige Tausend sauber beschriftete Beispiele aus.
Welche Hardware braucht man für Deep Learning?
Für das Training komplexer Modelle von Grund auf werden Grafikprozessoren (GPUs) benötigt – das ist kostspielig. Im Unternehmenskontext ist das jedoch selten notwendig: Vortrainierte Modelle und Cloud-Dienste (z. B. AWS, Azure, Google Cloud) ermöglichen den Einstieg ohne eigene Infrastruktur. Für die meisten Mittelstandsanwendungen reicht ein Cloud-Abonnement vollständig aus.
Lohnt sich Deep Learning für kleine und mittelständische Unternehmen?
Es kommt auf den Anwendungsfall an. Deep Learning ist kein Allheilmittel und kein Selbstzweck. Die entscheidende Frage lautet: Gibt es einen Prozess in Ihrem Betrieb, der große Mengen unstrukturierter Daten – Bilder, Dokumente, Sprache – verarbeiten muss? Wenn ja, kann Deep Learning skalierbar, kostengünstig und konsistent arbeiten. Wenn nein, ist oft ein einfacheres Verfahren die bessere Wahl.
Fazit: Deep Learning verstehen bedeutet, es gezielt einzusetzen
Deep Learning ist kein Zauber. Es ist strukturierte Geometrie, Mustererkennung und clevere Datentransformation – kombiniert mit einem Lernprozess, der sich iterativ verbessert. Wer versteht, dass Features wichtiger sind als Netzgröße, und wer den Unterschied zwischen sinnvollen und sinnlosen Anwendungsfällen kennt, trifft bessere Entscheidungen.
Der nächste Schritt muss kein großes Projekt sein. Oft reicht ein konkreter Prozess, eine belastbare Datenbasis und ein klares Ziel, um erste Ergebnisse zu erzeugen. Wenn Sie herausfinden möchten, wo Deep Learning in Ihrem Betrieb einen echten Hebel bieten könnte – sprechen wir darüber. Ein erstes Gespräch von 30 Minuten genügt, um Klarheit zu schaffen.