Große KI-Modelle lernen durch Modelltraining aus riesigen Mengen an Daten — Texte, Bilder, Webseiten, Bücher. Ein Großteil dieser Daten stammt aus dem öffentlichen Internet. Viele davon sind urheberrechtlich geschützt. Ist das legal?
Die Antwort ist kompliziert. Und sie hat Konsequenzen — sowohl für Unternehmen, die KI-Systeme entwickeln, als auch für Webseitenbetreiber, Fotografen und Content-Ersteller.
Alle rechtlichen Grundlagen kompakt — EU AI Act, DSGVO, Urheberrecht — im kostenlosen KI-Recht Factsheet von Wurzelwerk.
Inhaltsverzeichnis

Wie KI-Modelle Daten sammeln
Moderne KI-Systeme werden mit Text- und Bilddaten aus dem Internet trainiert. Die Sammlung erfolgt über automatisierte Programme — sogenannte Crawler oder Scraper — die Webseiten besuchen, Inhalte herunterladen und in Datensätzen speichern.
Das Ergebnis: Trainingsdatensätze mit Milliarden von Texten, Bildern und Webseiten — darunter Nachrichtenartikel, Blogartikel, Fotos, Bücher und wissenschaftliche Inhalte.
Die zentrale Rechtsfrage: Dürfen urheberrechtlich geschützte Inhalte für diesen Zweck genutzt werden?
§ 44b UrhG: Der deutsche Rahmen für Text- und Data-Mining
In Deutschland regelt § 44b des Urheberrechtsgesetzes das sogenannte Text- und Data-Mining (TDM).
Der Grundsatz: Öffentlich zugängliche Inhalte dürfen grundsätzlich für Text- und Data-Mining genutzt werden — also automatisiert analysiert und verarbeitet werden, um Muster zu erkennen.
Das klingt nach einem Freifahrtschein für KI-Entwickler. Ist es aber nicht, denn:
Rechteinhaber können der Nutzung widersprechen.
Dieser Widerspruch heißt Nutzungsvorbehalt. Und er muss — hier liegt die Tücke — maschinenlesbar sein (§ 44b Abs. 3 UrhG).

Das Problem mit dem Nutzungsvorbehalt
Ein Nutzungsvorbehalt ist die rechtliche Erklärung eines Rechteinhabers, dass seine Inhalte nicht für Text- und Data-Mining — und damit nicht für KI-Training — verwendet werden dürfen.
Der Nutzungsvorbehalt muss maschinenlesbar sein, damit automatisierte Crawler ihn technisch erkennen können. Klingt einfach, ist es aber nicht.
In der Praxis ist unklar:
- Reicht ein Hinweis in den AGB?
- Muss eine spezielle technische Datei hinterlegt sein?
- Welcher Standard muss verwendet werden?
- Welche Bots müssen angesprochen werden?
Diese Fragen sind rechtlich noch nicht abschließend geklärt. Das erzeugt Unsicherheit — auf beiden Seiten.
robots.txt und TDM-Rep: Die technischen Werkzeuge
robots.txt
Die Datei robots.txt liegt im Hauptverzeichnis einer Website und steuert, welche Crawler bestimmte Inhalte besuchen dürfen. Viele Webseitenbetreiber nutzen sie, um bekannte KI-Bots auszuschließen.
Grenzen von robots.txt:
- Bots müssen die Datei freiwillig respektieren
- Neue KI-Bots müssen nachgepflegt werden
- Die Datei wurde ursprünglich nicht für KI-Training entwickelt
- Rechtliche Wirksamkeit als Nutzungsvorbehalt ist nicht gesichert
TDM-Rep
Das Text and Data Mining Reservation Protocol wurde speziell entwickelt, um Nutzungsvorbehalte für Text- und Data-Mining maschinenlesbar zu machen. Es bietet mehr Präzision als robots.txt — aber auch hier ist die rechtliche Anerkennung noch nicht vollständig gefestigt.
Nutzungsvorbehalte in Nutzungsbedingungen
Zusätzlich können Nutzungsvorbehalte in AGB, Impressum oder Metadaten formuliert werden. Ob solche Hinweise in natürlicher Sprache als „maschinenlesbar" gelten, ist rechtlich offen — da moderne KI-Systeme natürliche Sprache verarbeiten können.
Der Fall Robert Kneschke gegen LAION
Ein wichtiges Beispiel aus der Praxis: Der Fotograf Robert Kneschke veröffentlichte ein Foto auf der Plattform Bigstock. Die Nutzungsbedingungen der Plattform untersagten automatisiertes Scraping. Ein Link zu seinem Bild tauchte trotzdem im offenen LAION-Datensatz auf.
Kneschke klagte. Das Landgericht Hamburg wies die Klage im September 2024 ab — bestätigte aber, dass Text- und Data-Mining stattgefunden hatte.
Interessant: Im Datensatz war nicht das Bild selbst enthalten, sondern nur ein Link dazu. Trotzdem wurden urheberrechtliche Fragen zur Vervielfältigung diskutiert.
Der Fall zeigt: Die rechtliche Bewertung hängt von vielen Details ab — und ist noch im Fluss.
Möchten Sie das konkret auf Ihren Betrieb anwenden?
Kostenlos Termin buchen Justin Kollautz
KI Spezialist · Wurzelwerk
Justin Kollautz
KI Spezialist · Wurzelwerk
Was bedeutet das für Unternehmen?
Die rechtlichen Konsequenzen des § 44b UrhG und der Nutzungsvorbehalt-Regelungen gelten für zwei Gruppen: Webseitenbetreiber, die ihre Inhalte schützen wollen, und KI-Entwickler, die Trainingsdaten rechtssicher nutzen müssen.
KI-rechtliche Fragen für Ihr Unternehmen? Kostenlos Termin buchen →
Für Webseitenbetreiber und Content-Ersteller
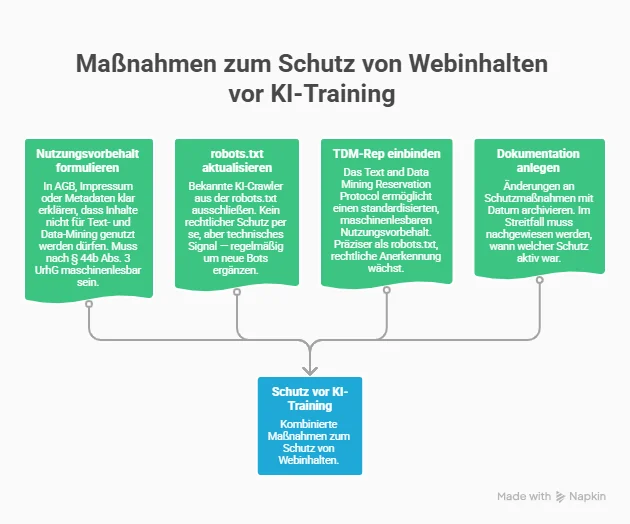
Wer nicht möchte, dass eigene Inhalte für KI-Training genutzt werden, sollte mehrere Maßnahmen kombinieren:
- Nutzungsvorbehalt klar formulieren (AGB, Impressum, Metadaten)
robots.txtmit bekannten KI-Bots ergänzen- TDM-Rep prüfen und ggf. einbinden
- Bild-Metadaten pflegen
- Änderungen dokumentieren und archivieren
Wichtig: Eine einzelne Maßnahme reicht nicht. Die Kombination erhöht die Schutzwirkung und die Nachweisbarkeit im Streitfall.
Für KI-Entwickler und Unternehmen mit KI-Projekten
Wer Trainingsdaten aus dem Internet verwendet, muss im Streitfall nachweisen können:
- Wann und wie wurde gecrawlt?
- War ein Nutzungsvorbehalt vorhanden?
- Waren technische Sperren aktiv?
Das bedeutet: Crawling-Prozesse dokumentieren, Herkunft von Trainingsdaten nachvollziehbar speichern und bei kommerziellen Projekten rechtliche Risiken systematisch bewerten.
Ein wirtschaftliches Dilemma
Das wirtschaftliche Dilemma besteht darin, dass Webseitenbetreiber zwischen zwei Zielen abwägen müssen: dem Schutz geistigen Eigentums vor KI-Training und der digitalen Sichtbarkeit in KI-gestützten Such- und Empfehlungssystemen.
Wer seine Inhalte vollständig vor KI-Bots sperrt, kann Nachteile riskieren: KI-Assistenten, Suchmaschinen der nächsten Generation und Empfehlungssysteme könnten gesperrte Inhalte schlechter finden und empfehlen.
Hier entsteht ein Spannungsfeld zwischen dem Schutz geistigen Eigentums und der digitalen Sichtbarkeit. Wie dieses Dilemma aufgelöst wird, ist eine strategische Entscheidung — keine rein rechtliche.
FAQ: KI-Training und Urheberrecht
Dürfen meine Blogbeiträge für KI-Training genutzt werden?
Grundsätzlich ja, wenn kein wirksamer Nutzungsvorbehalt vorliegt. Mit robots.txt, TDM-Rep und entsprechenden AGB-Klauseln können Sie dem widersprechen — wobei die rechtliche Wirksamkeit noch nicht überall abschließend geklärt ist.
Was ist Text- und Data-Mining?
Text- und Data-Mining (TDM) bezeichnet die automatisierte Analyse großer Datenmengen, um Muster, Strukturen und Zusammenhänge zu erkennen. Im Kontext von KI-Modelltraining bedeutet das: Texte, Bilder und andere Inhalte werden systematisch verarbeitet, um ein Sprachmodell oder Bildgenerator auf statistischen Mustern zu trainieren — geregelt in Deutschland durch § 44b UrhG.
Haftet ein KI-Anbieter, wenn mein geschützter Inhalt für Training genutzt wurde?
Das hängt von vielen Faktoren ab — ob ein wirksamer Nutzungsvorbehalt bestand, ob der Anbieter diesen erkennen konnte und ob tatsächlich eine urheberrechtlich relevante Nutzung stattgefunden hat. Die Rechtslage ist noch in Entwicklung.
Schützt robots.txt meine Inhalte rechtlich?
robots.txt sendet ein technisches Signal an Crawler und kann bekannte KI-Bots vom Zugriff ausschließen — eine rechtliche Verpflichtung zur Einhaltung besteht jedoch nicht automatisch. Die Datei gilt nicht als wirksamer Nutzungsvorbehalt im Sinne des § 44b Abs. 3 UrhG, ist aber als Teil eines kombinierten Schutzkonzepts aus robots.txt, TDM-Rep und AGB-Klauseln sinnvoll.
Fazit
Die Frage, ob KI mit urheberrechtlich geschützten Daten trainiert werden darf, ist keine theoretische. Sie betrifft Fotografen, Verlage, Webseitenbetreiber und KI-Unternehmen gleichermaßen.
§ 44b UrhG schafft einen Rahmen — aber die Details bleiben umstritten. Wer Inhalte schützen will, sollte mehrere Maßnahmen kombinieren. Wer KI-Trainingsdaten nutzt, sollte Dokumentation ernst nehmen.
Das Thema wird uns noch eine Weile beschäftigen.
Mehr zum Thema: Das KI-Recht Factsheet gibt dir einen kompakten Überblick über alle relevanten Rechtsbereiche — kostenlos als interaktive Webseite.
Weiterlesen in der KI-Recht-Serie:
- EU AI Act & KI-MIG: Was Unternehmen jetzt wissen müssen — Risikoklassen, Pflichten und konkrete Schritte für KMU
- KI im Alltag rechtssicher nutzen: Was bei Prompts und Outputs gilt — praktische Checklisten für den täglichen KI-Einsatz
Mehr aus dem Wurzelwerk-Blog:
- KI Terminologie für den Mittelstand — Grundbegriffe wie LLM, Training und Prompt erklärt